-
世纪开元发布的大语言模型,到底什么水平?
最后更新时间
2025-08-30 09:46:16
浏览量:
2356

这个榜单够权威吗?
对于不太熟悉AI领域的读者,可能会有疑惑:这个“Open LLM Leaderboard”究竟是什么榜单?为何在这个平台上获得高排名如此重要?首先,我们需要了解发布这一榜单的平台——Hugging Face。作为全球最大的AI开源社区,Hugging Face收录了超过32万个开源模型和5万个公开数据集,涵盖自然语言处理、计算机视觉、音频处理等多个AI领域。形象地说,如果一个AI模型、产品是一道美味的“菜肴”,那Hugging Face就是全球最大的机器学习模型和数据集“超市”,供全球的AI开发者挑选“烹饪”所需的“食材”。
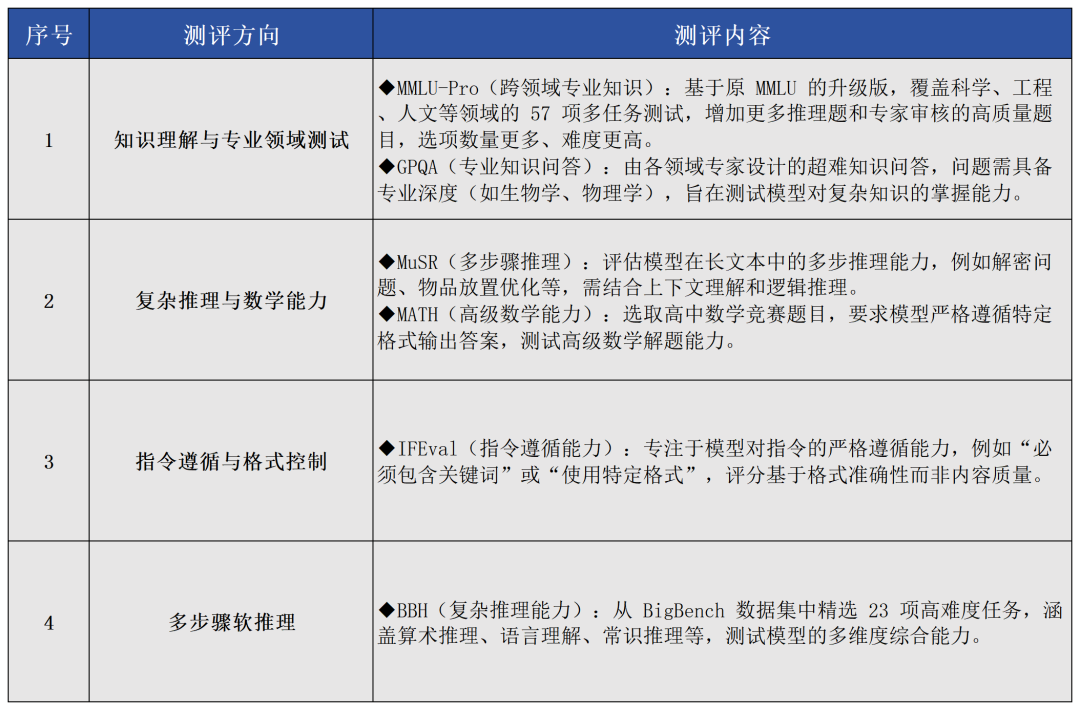
Hugging Face的影响力不仅在于完整的AI生态,更在于其倡导的开源精神和协作文化,各大科技公司如Meta(脸书母公司)、谷歌、微软等都选择在这里发布自己的开源模型,Hugging Face也逐步形成了连接开发者、研究者和企业的协作系统。举个例子,一位开发者如果有新的创意想转化为应用,他在Hugging Face上就可以直接调用预训练模型,无需从头开始研发,大大降低了AI应用的开发门槛,能节省90%以上的开发时间。换言之,Hugging Face这个“超市”不仅提供各类“食材”,还提供“半成品”与“预制菜”,更有宽敞明亮的大型“厨房”可供“厨师”们协作烹饪。对普通AI爱好者来说,它降低了探索AI的门槛;对专业开发者而言,它是缩短创意落地时间的“法宝”;对企业而言,它是降低技术投入风险的方案库。至于权威性,借用一位国内AI行业头部团队负责人的话来表达:“Hugging Face这个域名本身就是行业‘权威性’的认证。”Open LLM Leaderboard:开源大模型的权威评测排行榜随着各类开源大语言模型(LLM)的持续发布,Hugging Face这个“超市”中的“商品”越来越多,且经常出现“商家”对“商品”性能的夸大宣传的现象。为此Hugging Face发布了“Open LLM Leaderboard”(开源大语言模型排行榜),专注于评估开源大语言模型,使用多个公认的学术基准(详见表1),统一在Hugging Face的GPU集群上运行模型并自动评分,让全球AI开发者更容易筛选出真正具有技术优势的模型,从而找到自己想要的“对版商品”。由于“Open LLM Leaderboard”排行榜的评分标准受到业内广泛认可,评测过程透明,结果可复现,且持续吸纳新模型进入,因此被业界誉为评估开源大语言模型能力的“黄金标尺”。 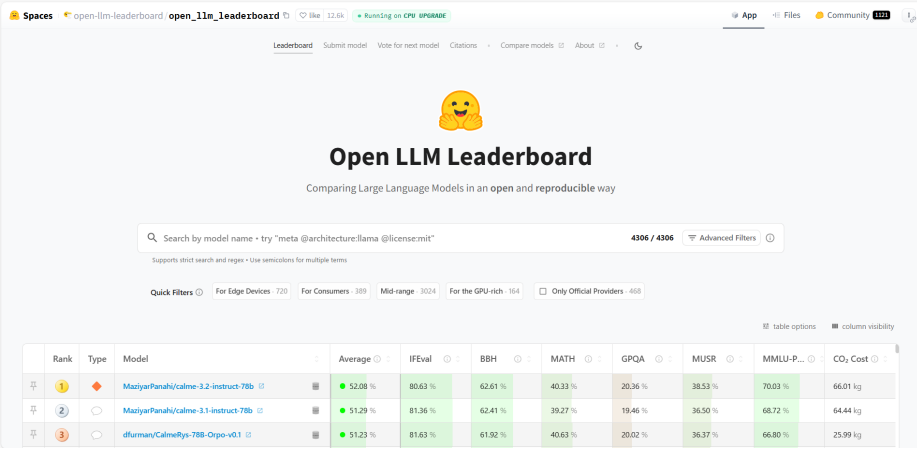
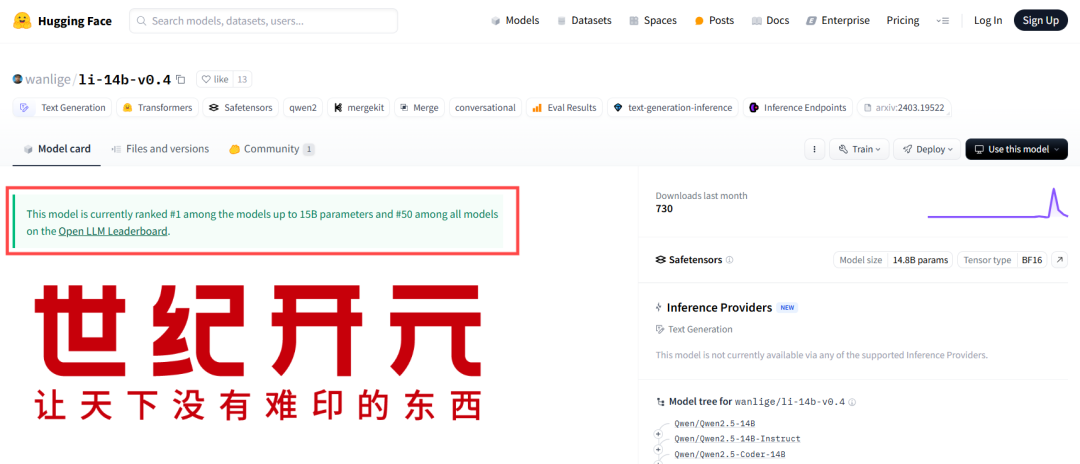
根据“Open LLM Leaderboard”排行榜的评测数据,世纪开元此次发布的大语言模型(li-14b-v0.4)综合评分(Avg)高达43.66分,位居15B参数级别榜首,全球综合排名第50名。截至发稿,综合排名榜首的模型综合评分为(Avg)52.08分,但参数量来到了78B,约为世纪开元发布模型参数量的5.6倍。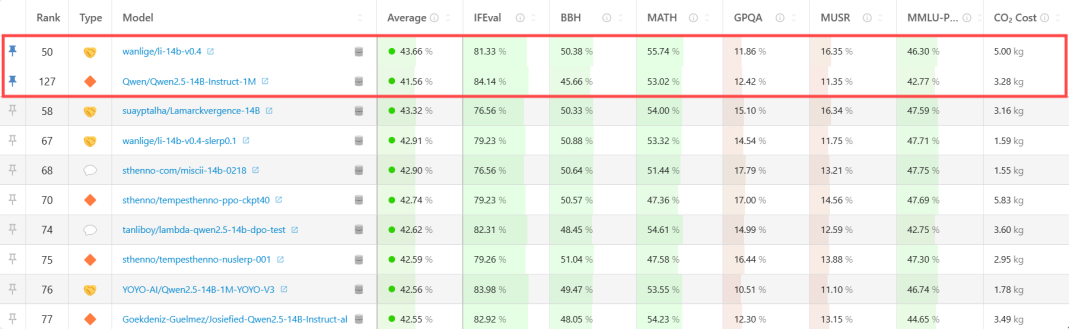
我们来做一个更直观的对比(见表2)。阿里千问系列模型(钉钉APP已经接入),作为已经推向市场的成熟AI应用,相信部分读者并不陌生,对其辅助工作的能力也有所认知。查阅Hugging face上的公开信息,世纪开元此次发布的大语言模型是一个精心设计的混合模型(Merge Model),开发基础正是阿里千问14B系列模型,但性能已实现明显超越。
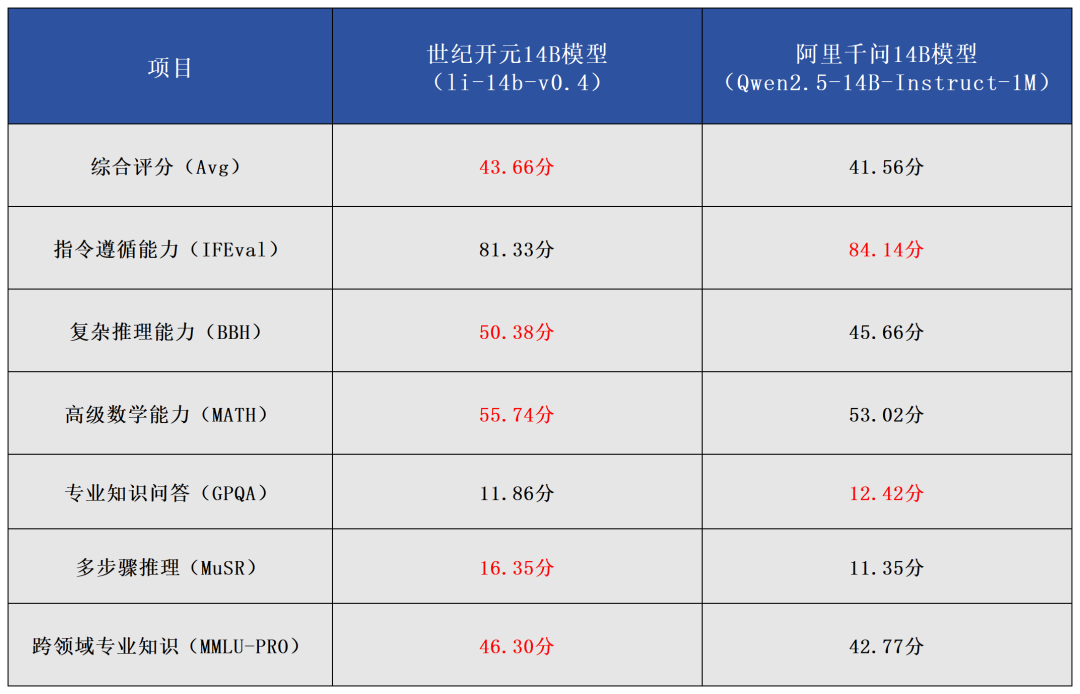
从技术角度来看,世纪开元的研发团队采用了“MergeKit”模型融合方法进行开发,即将多个专精不同领域的模型优势整合在一起,也就是我们上文提到的,AI开发者将“超市”中的多种“食材”烹饪成“菜肴”。组成这道“菜肴”的“食材”包括:
◆深度思考模型(DeepSeek-R1)的逻辑推理能力◆经过优化的阿里千问模型(Qwen2.5-Coder)的编程能力据世纪开元AI研发团队介绍,该模型专为企业数字化中的相对简单任务而优化,如智能客服系统的语音理解、行政工作中的文档处理等场景,通过融合多个专精不同领域的模型优势,实现了通用模型综合能力的提升。负责人介绍:“如果为每一个小任务配备Deepseek满血版这样的超大模型,会导致企业数字化成本过于高昂,但以往小尺寸的模型往往表现不佳,本次我们发布的14B模型,在成本、效率和应用效果上取得了较为理想的平衡。”世纪开元也秉持开源合作精神,已将最新开发的14B模型上传至Hugging Face供全球开发者免费下载,吸引了众多开发者的关注和使用。短短几日,该模型已获近800次下载,业界开发者用行动表明了高度认可。用一句话概括,本次世纪开元发布14B大语言模型的意义:“把制造业企业应用AI的成本打下来”。用一个词概括的话就是“省钱”。在当前AI大模型竞争中,动辄上百亿甚至上千亿参数的超大模型占据了大众视野焦点。虽然在同一模型下,大参数(如Deepseek-671B版本)确实能带来更为专业的响应,但同样部署成本也会成倍上涨。从企业数字化转型的角度来看,尤其是中小企业,许多AI应用场景如:文档处理、知识库查询、智能客服、设计辅助等,并不需要数百亿参数的大模型支持。“小尺寸”模型不仅能满足需求,还能大幅降低部署和运行成本,更适合企业生产环境的实际需要。接下来,我们结合公开数据来核算一下,一家300人的企业,做AI本地部署应用,使用不同参数的大语言模型,每年投入成本能相差多少?这里需要投入的成本,可以分为硬件采购、能源支出、运维成本三部分。模型参数越大,意味着需要更专业的GPU支持运算;更多的电力支持硬件运行;更专业的团队进行日常维护。为统一标准,我们选用目前企业接入较多的Deepseek不同尺寸版本进行成本比较。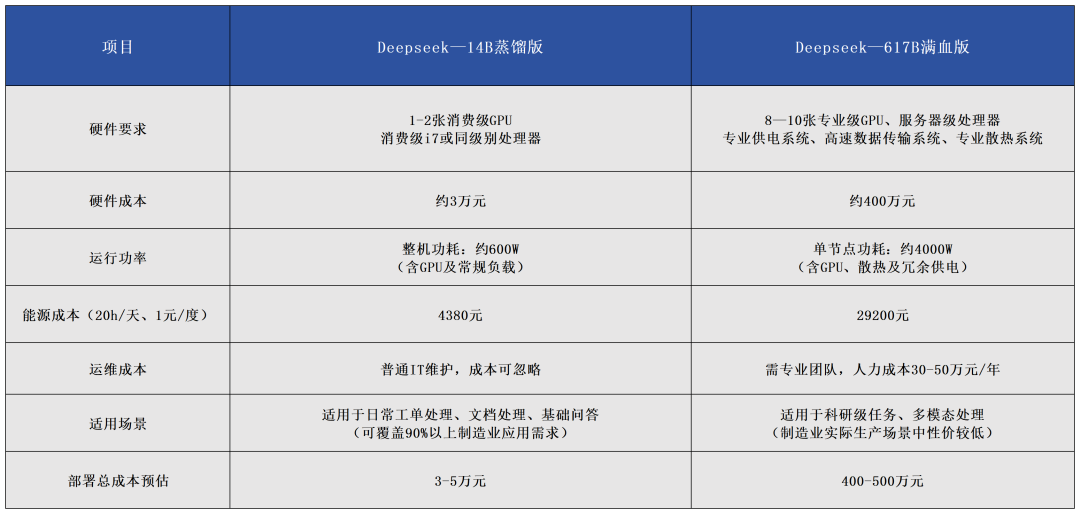
不难看出,企业部署14B参数“小尺寸”大模型,所需成本仅为3万元-5万元,不足617B“满血版”大模型部署成本的1%,却能够实现超过90%的企业任务覆盖。而世纪开元发布的14B参数大模型,还经过了企业任务流程的专门优化,在不涉及深度推理的情况下,部署成本将位于核算成本区间的低位,且模型本身完全免费开源。对于印包企业而言,世纪开元用行动证明了,其实无需投入巨额资金购买高端计算设备或支付高昂的API费用,也能将AI应用的能力融入业务流程,助力企业提质增效。世纪开元表示,后续将继续基于自研大语言模型,开发更多印包行业垂直应用,并持续优化模型性能,为印包业生产场景提供定制化、轻量化、专业化的大模型,推动中国制造业的智能化转型升级。